What is Confluent TableFlow?
Author: Sam Ward
Release Date: 13/09/2024
Understanding the Fundamentals: Apache Iceberg and Data Structures
To first understand what TableFlow does, and how Confluent makes use of it, we first need to dive into what Apache Iceberg is, what Data Lakehouses are, and how we can take advantage of them. Firstly, to define a Data Lakehouse, we must delve into what Data Lakes and Data Warehouses are.
Data Lakes and Data Warehouses: A Holy Matrimony
A data warehouse is a collection of raw data, stored in the infrastructure of a relational database. One of the main benefits of employing this data management system is that it allows for organisations to perform powerful analytics on incredibly large sets of data, as well as reporting and data mining. ETL (Extract, Load Transform) tools are used to extract data from a system, edit or enrich the data with other data which transforms it into new data, which in turn is loaded onto your data lake. Essentially, ETL is the process of taking data from many different sources and linking it together in such a way that it is in a suitable format to be loaded onto a data warehouse.

A data lake is a collection of original-format-data, stored without structure, in one huge centralised repository, at any scale. One of the key differences between data lakes and warehouses is that data lakes don’t require ETL tools to clean/structure data. While this makes data lakes a lot simpler, it also means that the data quality is significantly reduced (unless you perform data cleaning/filtering prior to uploading the data to the data lake).
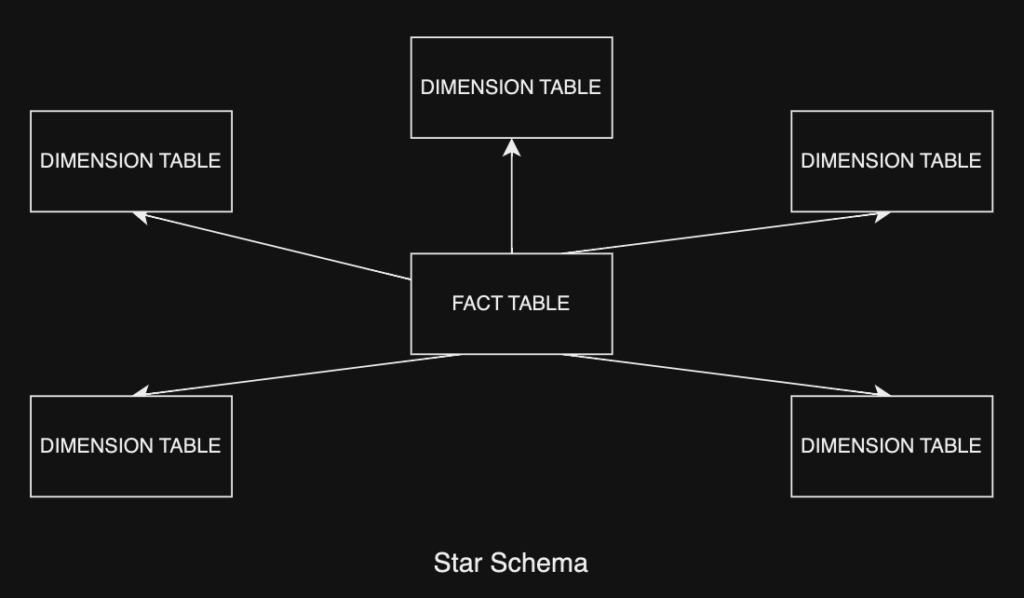
IBM defines the typical data warehouse as having “four main components: a central database, ETL tools, metadata tools and access tools” that are “engineered for speed so that you can get results quickly and analyse data on the fly.” While true, there are obviously some limits, such as time to analyse. The main way the data is organised in a data warehouse is through schemas, and there are two main different types of schemas, we have the Star Schema and the Snowflake Schema.
But how do these mix together? Well, a Data Lakehouse combines the best capabilities of a data lake and warehouse, allowing you to store your data in either a structured or an unstructured format. This means that data can be stored for analytical purposes in an organised format, while also enabling the use of the raw data in machine learning models. If a company has both the need to train a system to perform a given task using data, and also create reports and gain insights from data, the lakehouse is the ideal technology. With a Dat Lakehouse, you don’t need to maintain both a data lake and data warehouse, reducing costs and providing the data scientists/analysts with an easy-to-navigate system, where all the data they need is in one single, unified system.
Data Warehouse Schema: Star/Schema Additional Context
Star Schemas store data in a “star” format, where there is a central table, often referred to as the “fact table” and any number of directly connected tables, which we call “dimension tables” - the fact and dimension tables store information about metrics and information about descriptive attributes, respectively.
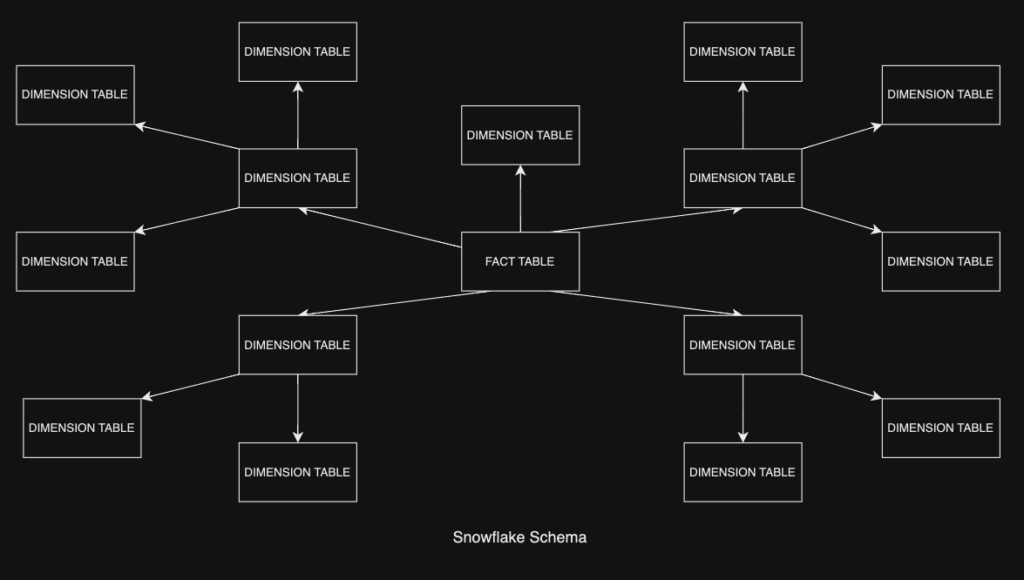
Snowflake Schemas store data in a more complex, branching system, often visualised as a tree of tables stemming from a central table - these tables are also called the “fact table” and the “dimension tables”.
Due to the simplicity of the star schema structure, it is much easier to implement and configure, and searching/querying the schema can often be very efficient due to the small amount of branches between tables. The key issue with these tables and the star schema however, is that it contains data that is denormalised, meaning that because of the smaller and less specific tables, we store a lot of data that can be considered redundant alongside unique data. While denormalised data leads to faster querying, updating tables and troubleshooting is often a lot harder than when using normalised data.
Apache Iceberg: Building on Data Lakes
In order to define what Apache Iceberg is, the best place to look is Apache’s official documentation pages - “Iceberg is a high-performance format for huge analytic tables” where it “brings the reliability and simplicity of SQL tables to big data” - it is designed to help simplify data processing of datasets stored in data lakes, through efficient and reliable storage and integrations with stream/data processing frameworks, of which Apache Flink is the most relevant. Open-sourced in 2018, it was originally developed by Netflix due to their issues with using tables that struggled with efficiency, reliability and scalability when the tables they were using reached petabyte levels of storage.
Typically, an organisation making use of a data lake uses a Metadata Catalogue, which is used to define the tables within the data lake - this is key to ensuring that across a data lake, all users (across the user base, such as an organisation) have a common, predefined view of all data stored in the data lake. The official Apache Iceberg website states “the first step when using an Iceberg client is almost always initialising and configuring a catalogue” which then allows the user to perform tasks like “creating, dropping, and renaming tables”.
The best way to visualise the way Apache Iceberg works is by thinking about how typical tables/data warehouses function: we have a branching list of different folders and topics, and within those folders/topics (named according to what we expect to find in the folder) we’ll find a certain type of data. Iceberg gets past the potential issues with this form of data tracking by keeping a complete list of all files in a given table, a level deeper than folders. This aids an array of different problems seen in pre-existing huge table infrastructure, by allowing the data engineer to: perform queries of the table much faster due to the redundancy of expensive list operations, reduce chance of data to “appear missing when file list operations are performed on an eventually consistent object store” (as Christine Mathiesen explains in her blog), ensure a consistent view of the data by using snapshots and atomic writes and perform a variety of other actions through Iceberg’s Java/Python API.
While this was a relatively quick and simple explanation of what Iceberg is and how it functions, for a more detailed view, Christine Mathiesen (as mentioned above) has an excellent blog that dives a little further into what Apache Iceberg can offer its adopters, covering topics such as Iceberg’s in-built schema evolution tools and how it also manages partitions, etc.
Confluent TableFlow: How Does This Link Together?
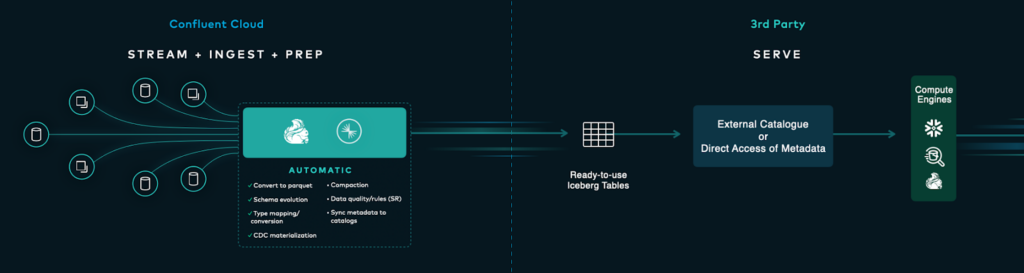
WIth all of the background knowledge and additional context covered, we now need to understand how this links back to Confluent’s offering of their new technology, TableFlow. Confluent TableFlow is currently in private early access, but their vision is to allow all Confluent customers to make TableFlow a “push-button” simple feature to “take Apache Kafka data and feed it directly into your data lake, warehouse, or analytics engine as Apache Iceberg tables” - so let’s dive right into what this means, and cover a little more background info required to see the whole vision.
Data in organisations are typically stored in two different estates, with Confluent defining these as:
• Operational Estate: where SaaS (Software-as-a-Service Apps), ERPs (Enterprise Resource Planning systems), and custom-built apps “serve the need of applications to transact with customers in real-time”
• Analytical Estate: where data is stored in large quantities ready for business analysis/report making, examples are data lakes, data warehouses, data lakehouses and AI/ML platforms

Confluent TableFlow: How Does This Link Together?
The Operational Estate and the Analytical Estate typically require some type of data to be accessible between both of them, but usually not in the same way. This can lead to a lot of unnecessary complexity when linking different databases/structures together. In simpler terms than in the source article, the following steps are necessary to get one single stream into a raw, usable state in a data lakehouse:
1) Configure the infrastructure to consume data from Apache Kafka, by setting up Consumers/Connectors and sizing them accurately for the intended topic that needs to be streamed to Iceberg
2) Feed the data through a system that ensures the data is in a single format and ensuring the data is consistent across all formatted files (using the Schema Registry)
3) Compact and clean up any additional/smaller files to maintain “acceptable read performance”
4) Edit and apply changes based on the type of data being sent
Confluent believe they can do a lot better, and here walks in TableFlow.
TableFlow: Unification of the Operational and Analytical Estates
TableFlow is a new way to continuously optimise read performance with file compaction, maintain efficient data storage and retrieval by sizing files, and managing your data flow in Confluent. It allows users to “easily materialise” their Kafka Topics, and associated schemas, into Apache Iceberg table” in a simple, efficient manner.
TableFlow utilises Confluent’s Kafka Kora engine and its storage layer to convert Kafka segments into other formats, as well as using “Confluent’s Schema Registry to generate Apache Iceberg metadata while handling schema mapping, schema, evolution, and type conversions”.
This means that your data can flow from Confluent, where it can be enriched and filtered, directly into a lakehouse, ready for analysis and reporting. One of the minor issues some users have with Confluent is visualising the data flowing through a topic, and with Apache Iceberg and Confluent converting topics into tables, it introduces a new way for users to see their data and manage it in a more accessible, user-friendly way.