
How to Format JSON Data Ready for Splunk
Author: Laurence Everitt
Release Date: 28/10/2024


• Having said that, numeric, boolean and null values should not be surrounded by double-quotes, such as below:

• If we want to group a number of fields together to make an overall object that describes a single entity (such as a "consultant"), then we use curly brackets to surround multiple key-value pairs and we use commas to separate the key-value pairs, such as this:

• If we want to make an array of values, that is possible by using square brackets and adding a name for the array, as below:

• If we want to make an array of objects, then we use the square brackets and commas to separate the items, like this:


• However, the below is bad, as the time outside of the JSON object will stop Splunk from showing it in the pretty JSON format (as this event is not valid JSON:

• To make it easier for Splunk (and humans) to find the date, we recommend that you place the date at the beginning of the event. This also makes the definition of the TIME_PREFIX and MAX_TIMESTAMP_LOOKAHEAD easier to configure, so this structure is not ideal:

• NOTE: As a test of this date placement recommendation in regex101, when it searched for the TIME_PREFIX at the start of the event, it took RegEx 13 steps to find the date, but when I moved the TIME_PREFIX to the end of the event, it took between 49 and 116 steps (depending upon complexity of REGEX), making this Aggregation Queue operation relatively expensive, so this optimisation is valid.
• It is not recommended that your events have duplicate value key names, which can make searching of data difficult and JSON requires that all keys are unique. Instead, for events that contain multiple keys with the same name and purpose, use JSON arrays (as mentioned above), so this is good practice:

• And the following valid JSON, but not recommended, as it either restricts the number of children or makes searching for the childrens’ names harder in Splunk:

• And the following is not valid JSON, with its duplicate key names:

• In most cases, each log event/item of data will be transmitted as a JSON object in itself, so make sure that each event is on a new line (that is a Carriage Return/Line Feed on Windows or Line Feed on MacOS/Linux) and that line breaking is easier for Splunk (however, events can be broken into multiple lines for readability), so the following events are good:

• However, the below is not recommended, as event breaking can be difficult to configure, as creating a RegEx to identify the event break may be complex (and this is especially true if events include nested JSON objects such as this):

• Be consistent and make sure that the data is consistent in its structure (i.e. all key-value pair character formats have the same layout, such as the following:
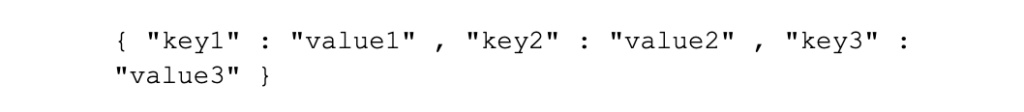
• NOTE: During this article, I have used the inter-character spacing for readability sake. Equally valid is the following spacing, which is not as easy to read in the file, but Splunk will still show it nicely when you search for it:
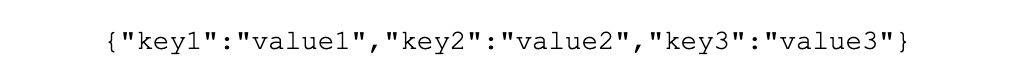
• However, the following, inconsistent, spacings should be avoided:
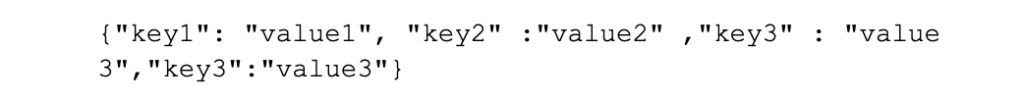
• Use double-quotes for all values, not just values which contain spaces, as this provides consistency in value format and searching, so this is good:
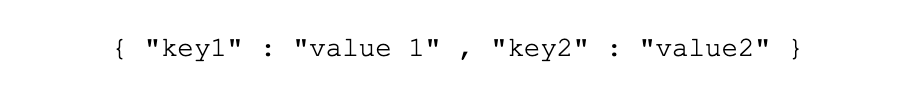
• This JSON object is not valid because strings must be surrounded by double quotes:
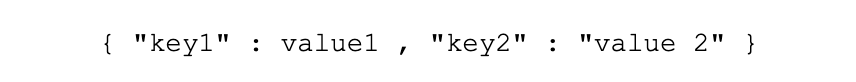
• Where possible, make sure that key names do not include spaces, are the same consistency (either using lowercase with underscores for spaces or camelcase). Both of these are value formats for key names:

• However, adding spaces into names can make searching in Splunk cumbersome (you will need to add quotes around the field names in the SPL):
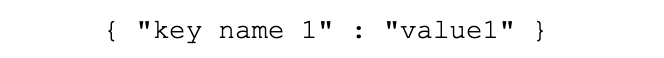
• Ensure that ALL events are generated with the same character set, such as UTF-8 or ASCII for this sourcetype.
• It is recommended that you add the time zone information to each event (especially if the system is deployed to systems around the world). This makes it easier for Splunk to ascertain when the event occurs around the clock and reduces complexity of administration, so these formats are both valid:

• Use double-quotes for values, not single quotes, so the following is correct:
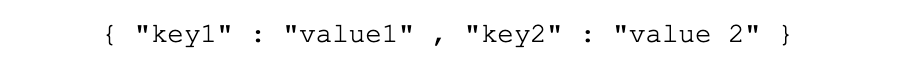
• Although this does look similar, do not use single-quotes (and is invalid JSON, anyway):
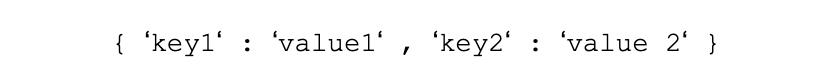
• Avoid indentation into the JSON log file as Splunk will automatically format the event for reading in the GUI and unnecessary indentation increases licence on spaces/tabs and new lines. So this is good:

• However, this is not recommended:


Configuration for props.conf
In order to configure Splunk to receive my new events, I need to set up the props.conf to include my new sourcetype. For more information, check out another of my blog entries here or here. For this sourcetype, I would configure the following settings in the props.conf on the first full Splunk instance that received my events:
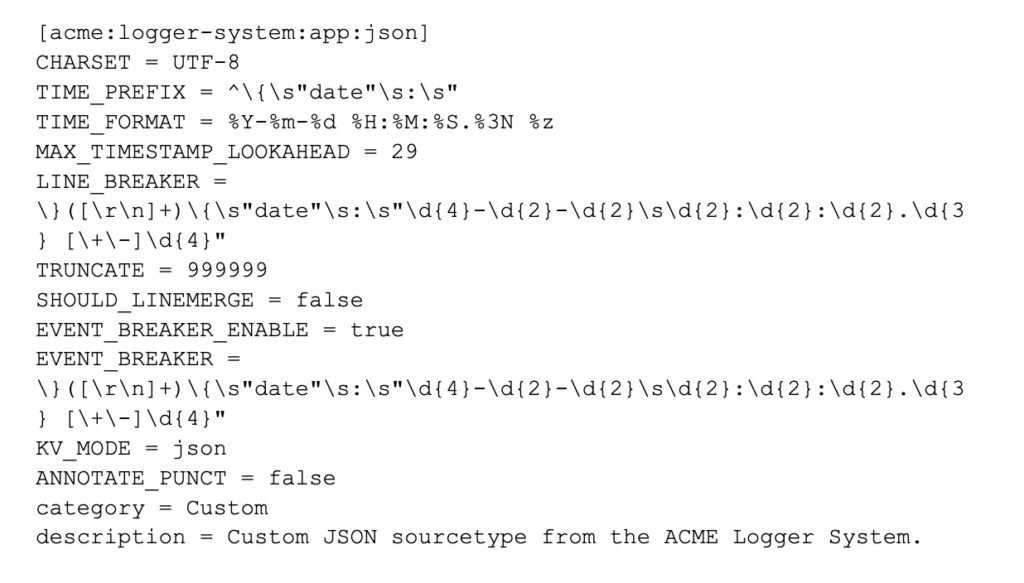
For my Worked Example, I created the props.conf configuration and then used the Add Data functionality of SplunkWeb to import the data and here you can see it!
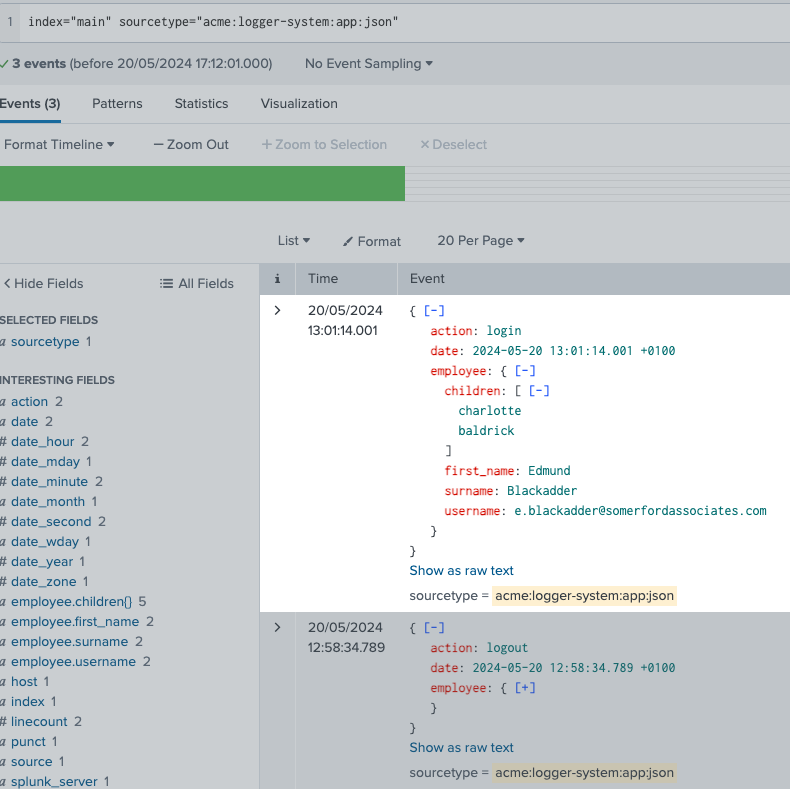
Because we have set the KV_MODE = JSON (and we are Searching in Smart or Verbose Mode), out-of-the-box, Splunk has already extracted the data that it has found as the following and means that we do not need to do complex field extractions to get the data, unformatted, out of the JSON:


