
How Does Kora Enhance Kafka & Confluent Cloud?
Author: Sam Ward
Release Date: 03/09/2024
Confluent Cloud: A Look Back
In order to understand what Kora is, we first need to take a step back, and contextualise why Confluent needed a Cloud-Native Apache Kafka Engine in the first place. Confluent’s early Kafka offering was open-source Kafka on a Kubernetes-based control plane with simplistic billing, observability, and operational controls - but only available on AWS. While this was the best offering in 2017 when Confluent Cloud was first launched, technology has been constantly evolving in the last 7 years. Apache Kafka has received around 900 additional KIPs (Kafka Improvement Proposals) since Confluent Cloud first went to early access in May of 2017.
Confluent Cloud: Evolution of the Service
Confluent have been innovating their cloud service ever since its inception, and while Confluent On-Prem functions in a similar way to Confluent Cloud, it has a whole array of different developmental constraints and challenges. From Confluent’s own blogs, it defines a few of these specific cloud challenges as: “built from the ground up to be multitenant, be largely driven by data-driven software-based operations rather than human operators, provide strong isolation and security across customers with unpredictable and even adversarial workloads, and be something a team of hundreds can innovate in rapidly”.

Defining Kora: Confluent’s Kafka Engine
The main problem with open-source Kafka is that it was developed during the same general time period at which Cloud Computing/Storage was being popularised, and so it was built with the idea of performing in a more static/hardware focused environment - this led to a developmental focus in Confluent’s team to ensure that Kafka not only ran on the Cloud platform, but thrived.
Enter Kora, Confluent’s Apache Kafka Engine built for the Cloud. Kora is the very engine that Confluent Cloud runs on, and has been carefully crafted by the developers to provide never before seen performance, elasticity and scalability. In order to fully understand how Kora works, we need to look deeper into the challenges and constraints that the development of Kora faced, as well as some of the solutions. Confluent have a published paper on the documentation of the design and development of Kora, and the following bullet points are a simplified and more concise list featured in the “Design Goals” section of the paper, enforced with sources and information supplied by Confluent:
• Availability & Durability: Confluent’s users rely on the platform to store and run business-critical data and microservices. To ensure that these users can truly rely on Confluent, Kora has been built and tested to achieve at LEAST a Triple 9 SLA of 99.9%, ensuring that even the most complex clusters and services stay consistently available
• Scalability: As businesses grow and requirements change, being able to scale up and down your clusters is incredibly important, and Kora facilitates this to ensure your environment is as cost-effective as possible
• Elasticity: Kora allows users to expand and shrink their clusters/environments based on size of workloads, and maintain a high level of performance while doing so
• Performance: Kora is built to be significantly more efficient than open-source Kafka, achieving speeds up to 16X faster (up from 4X faster 10 months ago, see 22:20 onwards)
• Low Cost: With Kora’s elasticity and Confluent’s announcement of prices being slashed in the keynote from the Kafka Summit 2024 (linked above), Confluent Cloud is more affordable than ever. Enterprise Clusters are a great example of this affordability, with a throughput price • of 50% (for new customers).
• Multi-Cloud Support: Kora runs on AWS, GCP, and Azure, while also ensuring multi-tenancy.
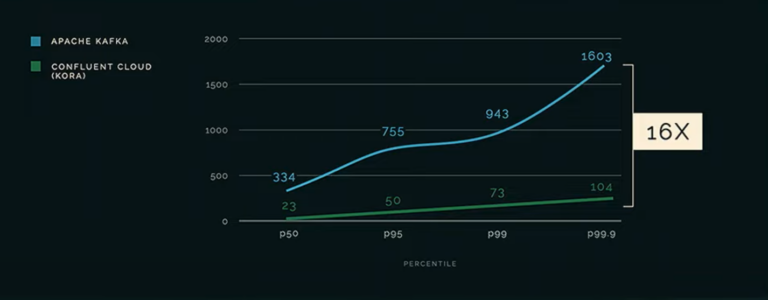
For those wanting to grasp a more detailed and technical understanding of Kora and what challenges the developers had to overcome, you can read the award-winning paper on the creation of Kora here. To recap, not only is Kora faster, more cost-effective and elastic than open-source Kafka, it is also 100% compatible with all currently supported versions of the Kafka protocol.

As a final takeaway, in the Kafka Summit 2024 Keynote, Konstantin Knauf, Apache Flink PMC and Product Manager for Stream Processing at Confluent describes how users can adopt Flink, which works hand-in-hand with the Kora engine, to develop their own truly cloud-native storage and data streaming services, and how Confluent’s partners can help customers get the most out of Confluent Cloud. Here is a quote from his section of the Keynote: “Our global ecosystem of service integrated partners is here to help you design, implement and solve your use cases”. For a basic overview on Flink and Confluent, and to understand how it all links together, see also our blog Apache Flink and Confluent: The Use Cases and Benefits of Integration with Confluent’s Data Streaming Platform.


