
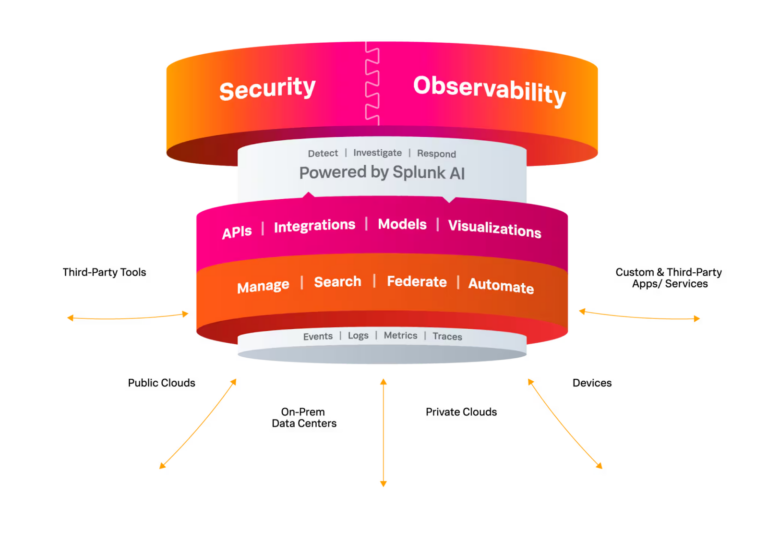
What is the Data Presentation Layer?
Author: Jake Hammacott
Release Date: 18/11/2024

For example, in the water treatment industry, sensors may be placed along major rivers, lakes and water treatment plants. These sensors could measure and collect data about the water height, flow and quality. If Confluent and Splunk are introduced to this scenario, instead of having to have engineers tracking each sensor manually, or through rather primitive IT infrastructure that cannot support the visualisation of “the bigger picture”, then problems may arise. For instance, these engineers or analysts may have a very limited view on the overall state of water quality throughout the entire water system. Problems further up a river may lead to a knock on event that impacts the rest of the river and could lead to the pollution of safe drinking water. Confluent and Splunk would empower engineers to be able to have the required access to data related to their entire job. In the same scenario, where problems further up the river decrease the water quality and potentially affect other areas of the system, the engineers would be alerted and notified about the concern and would be able to make any relevant changes and decisions in near-real time. This, ultimately, decreases the risk and impact caused by pollutants entering the water in the river as the engineers are prepared and made aware of all risky events.
Dashboards could, additionally, be developed to assist in providing a single-pane of glass into the entire water system - promoting quick analysis whilst also allowing for richer event data through the use of Splunk’s drill down searches and supporting dashboards. An overview dashboard could look something like this:
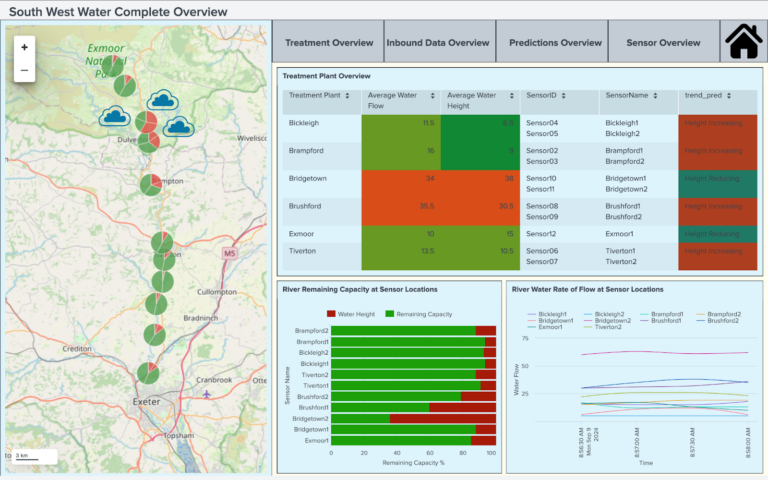
Here, data from treatment plants and sensors in rivers are brought together to provide an immediate overview of the current state of events happening in the water system. Additionally, Confluent and Splunk promote the use of external data to further complement existing data obtained internally. To further build on this example, the following dashboard utilises historic data available through a Met Office API to document and allow for statistical analysis when comparing current rainfall with previous years:
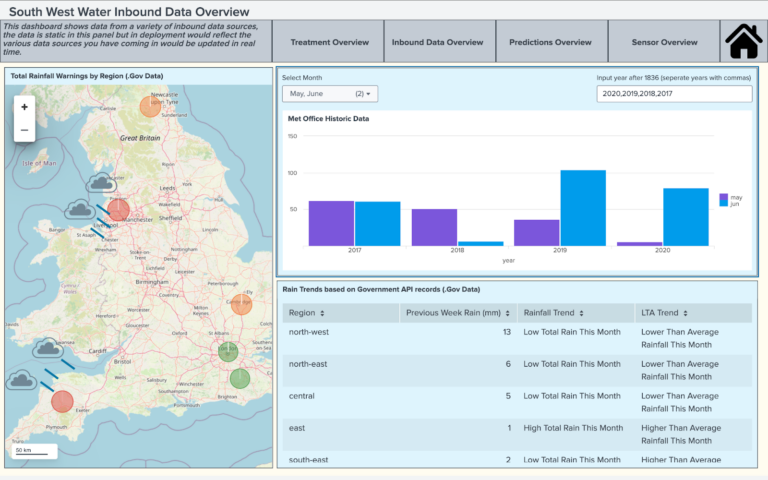
In this simulation, the presentation layer has been used to bring data from many different water systems across the UK to be further enriched by existing data that is readily available. It has then been sent and indexed within Splunk, where alerts, dashboards and reports have been set up and maintained to provide real-time updates sent directly to key decision-makers.


